こんにちはかねこです。私はCRuby(ruby/ruby)のコミッタをやっているのですが、最近はCRubyをメインのターゲットとしてLALR parser generator Lramaの開発をしています。 現役のLALR parser generator開発者として、日頃私以上にLR parserのことを考えている人はそうはいないでしょう。
この記事を読んでいる皆さんは構文解析、なかでも特にLR parserを理解するためにいろいろな教科書や記事を読んできたと思います。 一方でどんなに調べてもどこか腑に落ちない部分が残っているのではないでしょうか。
LR構文解析を勉強すると構文解析表に出会うとおもいます。

構文解析表を作る方法そのものは教科書に説明が載っており、その通りに手を動かせばこのような表を作ることはできるでしょう。 また出来上がった構文解析表をもとに実際に構文解析する手順も理解できると思います。 しかしこの表が一体何者であり、元の文法定義とどのような関係にあるのか、構文解析表の作り方の背後にはどのようなアイデアがあるのかというと説明に困るのではないでしょうか。 正直に言って教科書を含めてもLR parserの解説というのはとても分かりにくいものであると思います。 大堀先生によるLR構文解析の原理はLR構文解析とオートマトンの関係や、プッシュダウンオートマトンを用いることによる計算の最適化について詳しい説明を加えた優れた解説ですが、それでも構文解析表のもととなる非決定性オートマトンの構成方法に関しては従来通りitem(項)を用いるという方法をとっており、結果として生成規則との関係を直感的に理解することが難しくなっているように思います。
本日は今までとは違った切り口でLR parserの仕組みを解説し、皆さんがLR parserの基本原理の理解を深められたらと思い記事を書きました。
Rubyのサブセットをパースする
いきなりLR項やカーネル項の話をしても理解が深まると思えないので、まずは簡単な文法とそのparserを作りながら、基本的な動作原理を理解しましょう。 ここではRubyの(ごくごく)サブセットの実装を通じて、parserへの理解を深めます。
1. classだけが定義できる言語
最初はクラスが1つだけ定義できる言語を考えてみましょう。 以下の通りの入力だけを受け付けるparserを考えます。
class A end
このような入力をパースするにはどうしたらいいでしょうか。そうですね決定性有限オートマトンを用意すればいいですね。

上図のオートマトンはclass A endという入力のみを受理します。受理をしない例をいくつかあげてみましょう。
class: q1は受理状態ではないためA: q0ではclassのみを受け付けるため: q0は受理状態ではないためclass A end class: q3ではEOI(End Of Input / 入力の終了を表す特殊な記号)のみを受け付けるため
2. classの中に1つだけメソッドが定義できる言語
先ほどの例を拡張してclassの中にメソッドを1つだけ定義できる言語を考えてみましょう。 以下の通りの入力だけを受け付けるparserを考えます。
class A def m end end
先ほど同様にオートマトンを用意します。

この例もオートマトンが1つあれば十分ですが、ここではあえてオートマトンを2つに分解してみましょう。
図中上段の青色のオートマトンはclass A ... endのパースを行い、図中下段の赤色のオートマトンはdef m endのパースを行います。
class Aまでパースが終わった時点で下段のオートマトンに処理が移ります。def m endの処理を下段のオートマトンが終えると、再び上段のオートマトンに戻ってきてclassに対応するendとEOIを受け付けて全体の処理が完了します。

具体的な処理の流れをみていきましょう。
まずはclass Aまでを上段の青色のオートマトンで処理します。この次はdef m endをパースすることになるので、一旦処理を下段の赤色のオートマトンに移します。

つぎにdef m endの処理を赤色のオートマトンで行います。無事に赤色のオートマトンの最後まで遷移したので、ここで処理をもとの青色のオートマトンに移します。

最後にclass Aに対応するendを処理し、EOIを受け付けて全体の処理が完了します。

3. classの中に1つだけメソッドもしくは定数が定義できる言語
次はclass定義のなかにメソッド定義もしくは定数定義を書けるように拡張してみましょう。
class A def m end end
class A CONST = 1 end
classをパースするオートマトン(青色)defをパースするオートマトン(赤色)- 定数定義をパースするオートマトン(緑色)
を用意します。class Aまでパースした時点で赤色/緑色のどちらかに制御が移ります。次の入力をみて移動先のオートマトンを決めてもいいですし、とりあえず赤色のオートマトンに移動してdefでなければ緑色のオートマトンに移動するという方法をとってもいいでしょう。ここでは上から順番に試すという後者の方法をとることにしましょう。

4. class定義がネストできる言語
これまでの例ではオートマトンを分割するメリットをまだ全ては説明できていません。 オートマトンを分割することのメリットを理解するために、次の例ではclassの定義の中にclassの定義をネストできるようにしましょう。説明を簡単にするために、一番内側のclass定義には必ず定数を定義するものとします1。 ネストは何段階でも可能なので、次の例はいずれも正しい入力となります。
class A class A CONST = 1 end end
class A class A class A CONST = 1 end end end
classをパースするオートマトン(青色)- 定数定義をパースするオートマトン(緑色)
の2つがあればよいですが、今までの例と異なりclassをパースするオートマトンから同じくclassをパースするオートマトンに処理が移ることがあります。

実際のコードをパースする様子を見てみましょう。対象となるコードは以下のコードです。
class A class A CONST = 1 end end
1行目のclass Aまでパースを終えたところで次のclass Aをパースをするためのオートマトンを用意して制御を移します。

2行目のclass Aまでパースを終えたところで次のCONST = 1をパースをするためのオートマトンを用意して制御を移します。
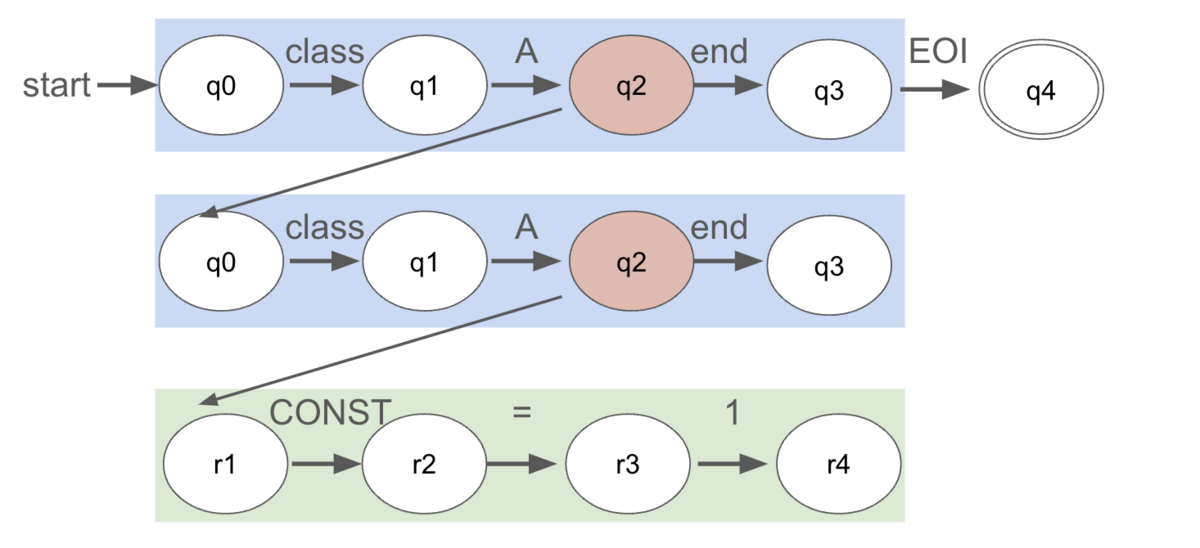
3行目のCONST = 1をパースを終えた時には次のような状態になります。

CONST = 1のパースが終わったので、3つめのオートマトンの役割は完了です。1つ前のオートマトンに戻って4行目のendをパースします。

4行目のendまで処理が終わると2つめのオートマトンの役割は完了です。最初のオートマトンに戻って5行目のendをパースします。最後にEOIがきて入力全体のパースが完了します。

BNFとの対応を考える
ここまでは"class定義がネストできる言語"というように自然言語で言語を定義してきましたが、言語を定義するの適した記述方法がありますね。そうですね、BNFです。
program : class_def
;
const_decl : "CONST" "=" "1"
;
class_def : "class" "A" body "end"
;
body : class_def
| const_decl
;
このBNFをじーっと見るとそれぞれのルールがオートマトンと対応していることがわかると思います。
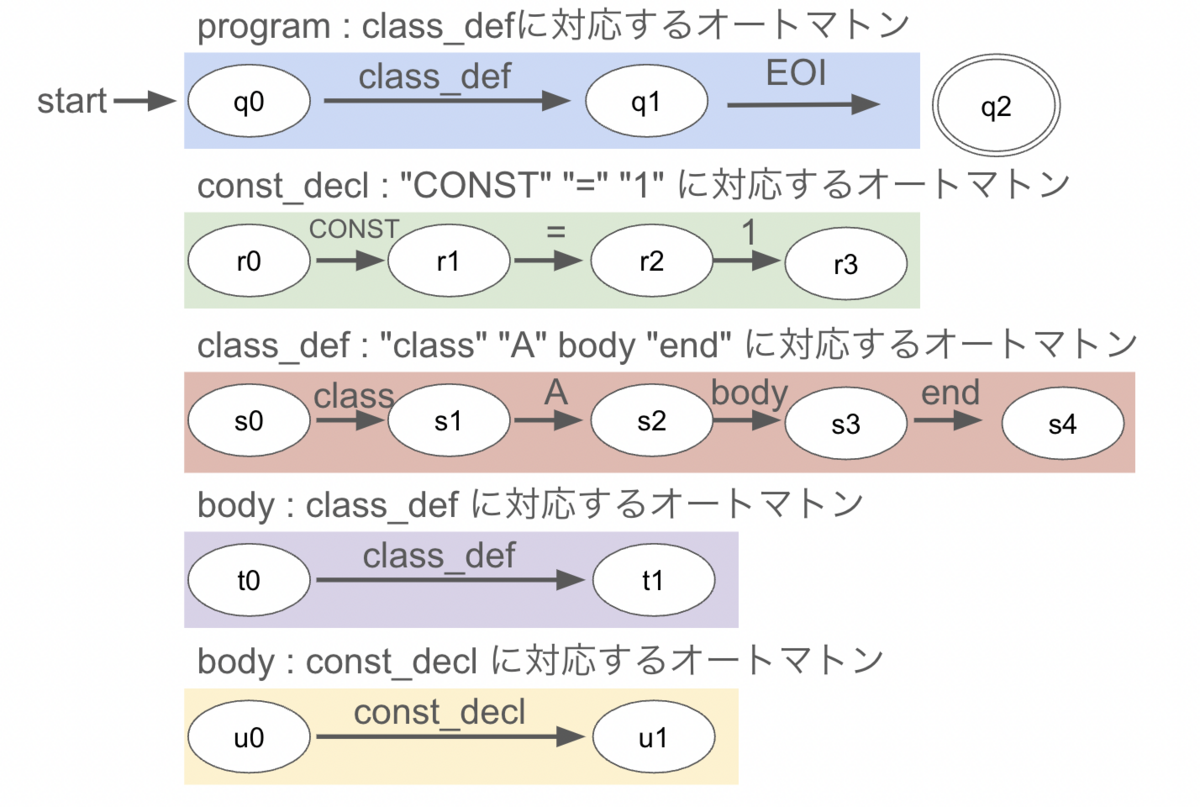
またclass_defやbodyといった非終端記号が次のオートマトンを生成するポイントと一致していることもわかると思います。
class A class A # <- ここまでをパースした状態 CONST = 1 end end

Earley法
ここまでは文法のルール1つに対してオートマトンを1つ用意し、複数の候補があるときは上から順番に全部試すというバックトラックのある方法を説明してきました。 この方法はLR法ではなく、Earley法という方法です。Earley法の詳しい説明はMakeNowJustさんによる以下の記事をご覧ください。
LR法へ
バックトラックなしでパースする方法としてLR法があります。LR法にはLR(0), SLR(1), LALR(1), LR(1)など様々な種類がありますが、ここではLR法全体で有効な考え方について説明します。
結論を先取りしていうと、LR法というのは各オートマトンを合成して、一つの大きなオートマトンにしたものです。
オートマトンの圧縮
オートマトンを合成して大きなオートマトンを作るという点を説明するために新しい言語を定義しましょう。 それは"class定義が一つありそのなかにメソッド定義もしくはシングルトンメソッド定義が1つある"という言語です。 具体的には以下の2つに対応するような言語です。
class A def m end end
class A def self.m end end
BNFで記述すると次のようになります。
program : class_def
;
class_def : "class" "A" body "end"
;
body : method_def
| singleton_method_def
;
method_def : "def" "m" "end"
;
singleton_method_def : "def" "self" "." "m" "end"
;
いまclass Aまでパースをしたとしましょう。
先ほどまでの方法ではまずmethod_def : "def" "m" "end"に対応するオートマトンを試し、それでうまくいかない場合はsingleton_method_def : "def" "self" "." "m" "end"に対応するオートマトンを試すのでした。


ここでオートマトンを1つに合成してみるとどうなるでしょうか。
例えばclass Aまでパースをした状態は図のような1つの状態として捉えることができます。
この状態は
class Aまでパースした状態であり、かつ- 次に
bodyが来れば遷移することができる状態であり、かつ - 次に
method_defが来れば遷移することができる状態であり、かつ - 次に
defが来れば遷移することができる状態であり、かつ - 次に
singleton_method_defが来れば遷移することができる状態であり、かつ - 次に
defが来れば遷移することができる状態である
といえます。

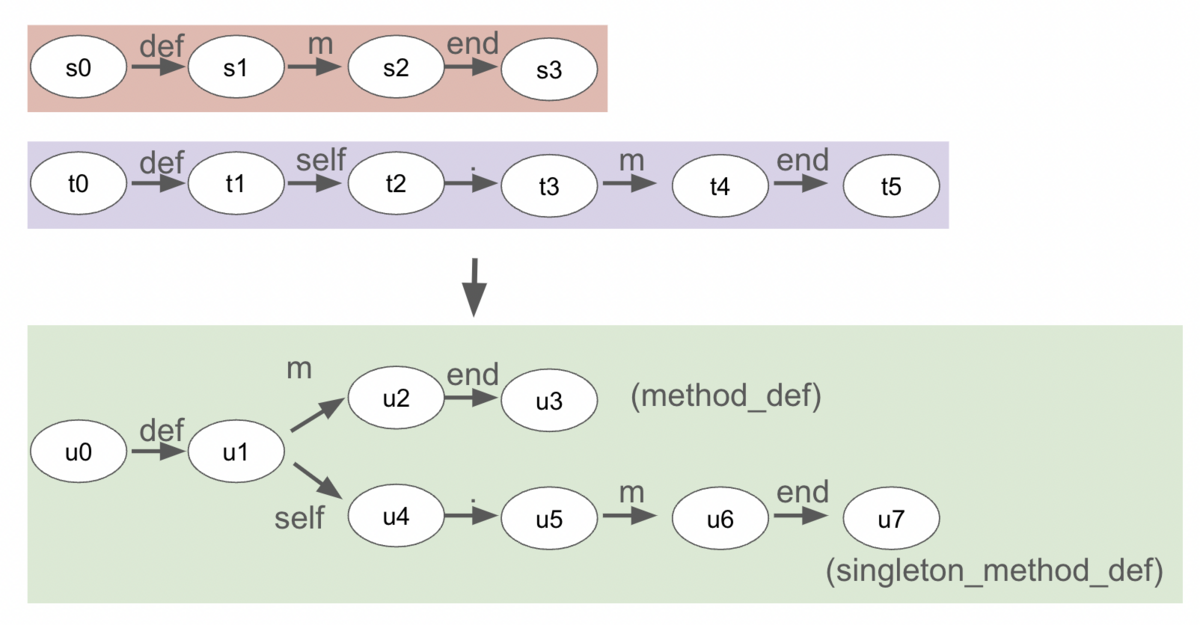
さらにmethod_def : keyword_def method_name keyword_endのオートマトンとsingleton_method_def : keyword_def keyword_self '.' method_name keyword_endのオートマトンを合成してみます。
合成後のオートマトンではdefが来たときにu1に遷移します。その次がmであればu2(上の分岐)へ、selfであればu4(下の分岐)へ遷移します。
このようにオートマトンを合成することで、バックトラックなしで複数の候補を試すことができるようになりました。
Lramaをつかって各状態を表示するとclass Aまで読んだ状態はState 4で、これは先ほど説明した5つの状態が重なった状態です。このときにdefを読んだ場合はState 6に遷移します。State 6はu1に対応しています。State 6ではmとselfで遷移先が異なり、そこから先は通常のメソッド定義もしくはシングルトンメソッド定義のそれぞれに特化した処理になっていることがわかります。
State 4 (p2/u0に相当)
2 class_def: "class" "A" • body "end"
3 body: • method_def
4 | • singleton_method_def
5 method_def: • "def" "m" "end"
6 singleton_method_def: • "def" "self" '.' "m" "end"
"def" shift, and go to state 6
body go to state 7
method_def go to state 8
singleton_method_def go to state 9
State 6 (u1に相当)
5 method_def: "def" • "m" "end"
6 singleton_method_def: "def" • "self" '.' "m" "end"
"self" shift, and go to state 10
"m" shift, and go to state 11
State 10 (u4に相当)
6 singleton_method_def: "def" "self" • '.' "m" "end"
'.' shift, and go to state 13
State 11 (u2に相当)
5 method_def: "def" "m" • "end"
"end" shift, and go to state 14
構文解析表の生成
BNFのルールに対応するオートマトンを合成して、一つの大きなオートマトンを生成しました。 この一つの大きなオートマトンの動きを表にまとめたものが構文解析表です。

例としてState 4 (p2/u0)とState 6 (u1)について構文解析表を見てみましょう。
State 4 (p2/u0)はclass Aまでパースした状態であり、body, method_def, singleton_method_def, defのうちどれが来るかによって遷移先が異なる状態です。構文解析表の青色の行をみてみると、body, method_def, singleton_method_def, defのそれぞれで遷移する先の状態が異なることがわかります。
State 4 (p2/u0に相当)
2 class_def: "class" "A" • body "end"
3 body: • method_def
4 | • singleton_method_def
5 method_def: • "def" "m" "end"
6 singleton_method_def: • "def" "self" '.' "m" "end"
"def" shift, and go to state 6
body go to state 7
method_def go to state 8
singleton_method_def go to state 9
State 6 (u1)はdefまでパースした状態であり、mとselfのどちらが来るかによって遷移先が異なる状態です。構文解析表の赤色の行をみてみると、mとselfでそれぞれ遷移する先の状態が異なることがわかります。

State 6 (u1に相当)
5 method_def: "def" • "m" "end"
6 singleton_method_def: "def" • "self" '.' "m" "end"
"self" shift, and go to state 10
"m" shift, and go to state 11
まとめ
無事に構文解析表を生成することができました。 いままで天下り的にBNFから作り出していた構文解析表でしたが、その正体は複数のオートマトンから生成した一つの大きなオートマトンの遷移を表すものだったのです。
構文解析表ができるまでの順番を整理しておきましょう。
- BNFのルールに対応するオートマトンを用意する
- 1で用意したオートマトンを合成して1つのオートマトンにまとめる
- 2でつくったオートマトンの遷移を表にまとめると構文解析表になる
今後みなさんがLR parserを実装していて迷った時には、それは複数のオートマトンから生成した一つの大きなオートマトンであるということを思い出してください。
ruby-jp slackの#lr-parserチャンネルにおけるnaruseさんとmake_now_justさんとの議論からこのような説明の仕方は生まれました。両名に感謝します。ありがとうございます。
- ε (empty)を加えると説明が複雑になるため、定数定義をネストのストッパーとして利用しています↩