Ruby Parser Roadmapをつくったのでご紹介します。
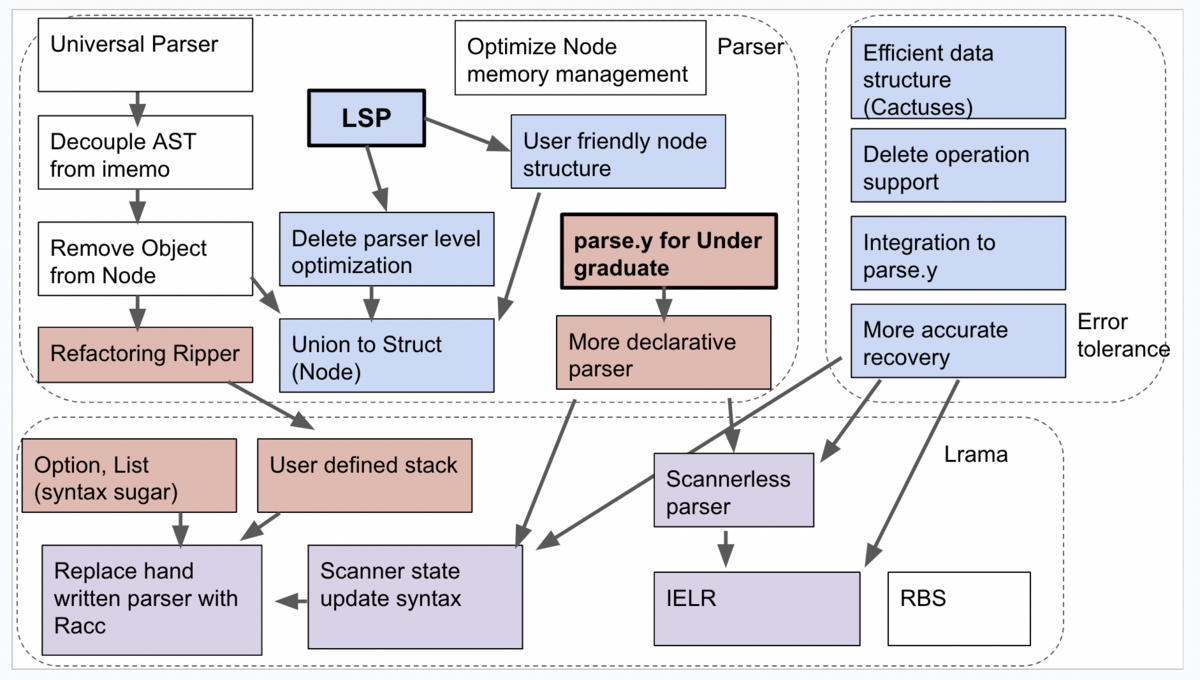
大きな2つのゴール
現在注力している領域が2つあります。ひとつはLSPのサポート(図中では青色)、もうひとつはparse.yをより平易にするための取り組みです(図中では赤色)。またその他のゴールとしてUniversal Parserがあり、さらに依存関係はないものの取り組みたいと思っているテーマがいつかあります。
なお図中の矢印は矢印の元から先に向けて依存があることを示しています。例えば"LSP"というゴールは"Delete parser level optimization"と"User friendly node structure"という2つに依存しています。図中の紫色の部分は2つの注力領域両方が依存しているものを表しています。
LSP
一つ目のゴールはLSPなどの各種ツールで使いやすいparserを提供することです。図の中では青色のボックスが該当します。 ゴールであるLSPから直接依存関係があるサブゴールとして
- User friendly node structure
- Delete parser level optimization
の2つがあり、それらはさらに1つのサブゴールに依存しています。
- Union to Struct (Node)
また直接の依存関係はないですが、"Error tolerance"に関する機能を開発することもLSPのサポートでは重要なので、青色になっています。
それぞれ順番に見ていきましょう。
User friendly node structure
既存のAST Nodeは使い勝手の悪い部分がいくつかあります。
AbstractSyntaxTree#childrenがarrayを返すため、arrayの要素の位置からその意味が把握しにくいものになっています。
例えばNODE_IFの場合、nodeが3つのarrayを返します。それぞれcondition, then, elseに対応するnodeです。
RubyVM::AbstractSyntaxTree.parse("if a then 1 else 2 end").children[2].children # => [(VCALL@1:3-1:4 :a), (LIT@1:10-1:11 1), (LIT@1:17-1:18 2)]
この場合#condition, #then, #elseのように要素名に対応したメソッドが提供されてたほうが使い勝手はよくなるでしょう。
node = RubyVM::AbstractSyntaxTree.parse("if a then 1 else 2 end").children[2] node.condition # => (VCALL@1:3-1:4 :a)
いまのNodeにはスクリプトと直接紐づかないNodeがあります。例えばNODE_SCOPEというNodeがあるのですが、これはメソッド定義やクラス定義のNodeの中にあらわれて引数の情報などを管理しています。引数の情報はNODE_DEFNに直接持たせて、NODE_SCOPEを消すのがよいでしょう。
$ ruby --dump=p -e 'def m(a); end' # @ NODE_DEFN (id: 1, line: 1, location: (1,0)-(1,13))* # +- nd_mid: :m # +- nd_defn: # @ NODE_SCOPE (id: 5, line: 1, location: (1,0)-(1,13)) # +- nd_tbl: :a # +- nd_args: # | @ NODE_ARGS (id: 3, line: 1, location: (1,6)-(1,7))
また実引数のNodeが複雑なのでもう少し簡単な構造にしたいと思っています。
# シンプルなケースではNODE_LIST $ ruby --dump=p -e 'm(a)' # +- nd_body: # @ NODE_FCALL (id: 0, line: 1, location: (1,0)-(1,4))* # +- nd_mid: :m # +- nd_args: # @ NODE_LIST (id: 2, line: 1, location: (1,2)-(1,3)) # +- as.nd_alen: 1 # +- nd_head: # | @ NODE_VCALL (id: 1, line: 1, location: (1,2)-(1,3)) # | +- nd_mid: :a # +- nd_next: # (null node) # &blockがあるときはNODE_BLOCK_PASSからはじまる $ ruby --dump=p -e 'm(a, &block)' # +- nd_args: # @ NODE_BLOCK_PASS (id: 4, line: 1, location: (1,2)-(1,11)) # +- nd_head: # | @ NODE_LIST (id: 2, line: 1, location: (1,2)-(1,3)) # | +- as.nd_alen: 1 # | +- nd_head: # | | @ NODE_VCALL (id: 1, line: 1, location: (1,2)-(1,3)) # | | +- nd_mid: :a # | +- nd_next: # | (null node) # +- nd_body: # @ NODE_VCALL (id: 3, line: 1, location: (1,6)-(1,11)) # +- nd_mid: :block
Delete parser level optimization
いまのRubyにはparserレベルでの最適化がいくつか入っていて、その結果一部のNodeが削除されます。
def m 1 # この行は意味がないのでASTに残らない 2 end # +- nd_body: # @ NODE_LIT (id: 4, line: 3, location: (3,2)-(3,3))* # +- nd_lit: 2
def m return 1 # メソッドの最後のNODE_RETURNは削除されてNODE_LITだけが残る end # +- nd_body: # @ NODE_LIT (id: 3, line: 1, location: (1,14)-(1,15))* # +- nd_lit: 1
LSPなどのツールに対して構文解析した結果を返すというユースケースにおいては、ASTのNodeレベルでの最適化は情報が落ちるので嬉しくありません。必要に応じて最適化をcompile.cに移し、parserでの最適化は消していく必要があります。
Union to Struct (Node)
"User friendly node structure"や"Delete parser level optimization"を行うためにはNodeの構造を変更していく必要があります。しかしいまのNodeの内部構造はそれらの変更に向かないものになっています1。
RubyのNodeはかつてGCで管理されていました。そのころの名残で全ての種類のNodeがたった一つの構造体を共有しています。他のNodeへのポインタやmethod名を表すIDなどはu1, u2, u3というunionで管理しています。それぞれのunionがどの型かというのはNodeの種類によって変わり、Nodeの種類に応じて適切なマクロを使い分ける必要があります。
また構造体を共有しているということは、あるNodeで4つ以上の情報を扱うためにunionを追加すると、ほかの全てのNodeでもその分のメモリが確保され、必要以上にメモリを使うことになります。
Nodeの種類に応じた構造体を別々に定義することでこの問題は解決されます。
typedef struct RNode { VALUE flags; union { struct RNode *node; ID id; VALUE value; rb_ast_id_table_t *tbl; } u1; union { struct RNode *node; ID id; long argc; VALUE value; } u2; union { struct RNode *node; ID id; long state; struct rb_args_info *args; struct rb_ary_pattern_info *apinfo; struct rb_fnd_pattern_info *fpinfo; VALUE value; } u3; rb_code_location_t nd_loc; int node_id; } NODE;
// NODE_IFの場合は3つとも他のNodeのポインタになっている #define nd_cond u1.node #define nd_body u2.node #define nd_else u3.node // NODE_CALLの場合はmethod名がidで他はNodeのポインタ #define nd_recv u1.node #define nd_mid u2.id #define nd_args u3.node
Error tolerance
Error toleranceに関して4つのサブゴールがあります。
Efficient data structure (Cactuses)
Error toleranceの実装はどのようなtokenをinsert/deleteすればいいかを探し出すというものです。tokenの種類によってはreduceをして探索を進める必要があるため、候補となるtokenごとにparserのstackのコピーをもつというナイーブな実装になっています。
このようなケースではCactusesデータ構造というデータ構造を使うのがよいので、置き換えていきたいです。詳しくは以下のリンク先を参照してください。
Delete operation support
"どのようなtokenをinsert/deleteすればいいかを探し出す"と書きましたが、いまのところはinsertのみで探索を行います。入力されたスクリプトを残した方がいいと思うので基本的にはinsertをメインにして探索をするのでいいと思うのですが、場合によってはtokenをdeleteしたほうが良いケースもあるとおもうので、両方をサポートできるようにしたいです。
Integration to parse.y
Lrama側には実装をしたのですが、実はまだRuby本体と結合できていません。ちゃんと繋ぎ込みをして利用できるようにします。
More accurate recovery
Error toleranceの実装はparserの状態遷移を利用しています。そのためlex stateやparser_paramsで管理している状態をparserの状態に合体することで、エッジケースなどでよりよいリカバリーが期待できます。そのためこのゴールは"Scannerless parser"や"Scanner state update syntax"といった他のゴールに依存しています。
parse.y for Under graduate
二つ目のゴールはparse.yをより理解しやすいものにしていくことです。具体的には教科書などで構文解析を勉強すれば、parse.yを理解できるという状態にしたいと思っています。 そのためにはLexerやGrammar Ruleのactionに手書きされているロジックを減らしていき、より宣言的なGrammarにしていく必要があります。これが"More declarative parser"というゴールです。
このゴールを達成するためには大きく2つの課題があります。ParserとLexerを統一してデザインすることと、Lramaの文法ファイルのDSLをリッチにすることです。
Scannerless parser と IELR
Ruby Parser開発日誌 (11) - RubyKaigi 2023 follow upで進捗について話してきた - かねこにっきの"LexerとParserは分離可能なのか"で書いたように、RubyにおいてLexerとParserは相互に影響しながら動きます。 BisonではLexerとParserの相互作用はGrammar Ruleのactionによって記述する必要があったので、それらは全てC言語による実装になっています。
LexerとParserを仕組みとして統合する試みのひとつに PSLR(1) (Pseudo-Scannerless Minimal LR(1)) という種類のparserがあります。またそのベースとなるparserにIELR(1)というLALR(1)を進化させたparserがあります2。
LALR, IELR, PSLRとparserのアルゴリズムを発展させていくというのが、ひとつのサブゴールです。
Scanner state update syntax
PSLRやIELRがparserのアルゴリズムの進化であるのに対して、こちらはDSLを発展させてLALRをより強力にしていくアプローチです。
例えばRubyにはkeyword_ifとmodifier_ifというようにifが2種類あります。これらはlex_stateという状態に応じてどちらになるかが決まります。lex_stateの更新をDSLとしてサポートすることで、parse.yの見通しをよくすることができるのではないかと考えています。
stmt | stmt modifier_if expr_value => stmt | stmt %lex(EXPR_END) modifier_if expr_value
Option, List (syntax sugar)
既存の文法についても改善の余地があります。,区切りのarg_valueの連続(args)や省略可能な改行(opt_nl)といったルールの書き方は頻出で、書き方もテンプレート化しています。
Menhirの機能を参考にDSLを拡張していきます。
args : arg_value
| args ',' arg_value
;
opt_terms : /* none */
| terms
;
=>
args : separated_list(',', arg_value)
;
opt_terms : option(terms)
;
Replace hand written parser with Racc
"Scanner state update syntax"や"Option, List (syntax sugar)"をやろうとすると、Lramaのサポートする文法を拡張していく必要があります。 いままではBisonの文法を移植していればよかったのですが、これからは自分で文法を考えて追加していかなくてはなりません。 いざ自分で文法を追加するようになるとわかるのですが、これから追加する文法が既存の文法とぶつかっていないかがすごく気になります3。LR parserであればそのような問題はconflictとしてレポートされるので開発段階で気がつくことができます。
そこで、Lramaの手書きパーサーをRaccで生成したLR parserに置き換えるというサブゴールがあります。 LramaのDSLの拡張すべてに対して有効なので、このサブゴールは他の多くのサブゴールから依存の矢印が伸びています。
その他のゴール
白色の表されたその他のゴールについてみていきましょう。
Universal Parser
Universal ParserとはTypeProf, Sorbetといった解析ツールや、mrubyなどCRuby以外のRuby実装でもCRubyのparserを使えるようにするというゴールです。 そのためにはいまのparserからCRubyの機能への依存を消す必要があります。
Decouple AST from imemo
最終的にはASTをimemoというinternalなobjectから剥がす必要があります。
Remove Object from Node
Nodeが参照しているCRubyのobjectのGCの関係で、ASTもまたCRubyのobjectである必要があります。なので先に各種NodeからCRubyのobjectへの参照を消す必要があります。
Refactoring Ripper
ParserとCRuby objectといえばRipperの存在がありますね。簡単にいうとRipperはparse時の情報をcallbackに渡し、その戻り値を次のcallbackに渡すということを繰り返します。callbackからの戻り値はもちろんRuby objectなので、GCなどを考慮しないといけません。いまはRipper用のRuby objectを管理する場所とparserのNodeを管理する場所が同じstackになっているので、これを何かしらの方法で分離する必要がありそうです。
たとえばRipperのときはRubyのArrayをつかってstackを管理するといった拡張をLramaのDSLでサポートすればよいかもしれません ("User defined stack")。
その他の課題
Optimize Node memory management
"Union to Struct (Node)"で話したとおり、いまのNodeは種類によらず同じ構造体を使っています。そのためNODE_NILやNODE_TRUEといった他のNodeへの参照をもたないNodeであっても他のNodeと同じだけメモリーを使用します。なんとかしたいですね。
RBS
Lramaの取り組みの一つとしてRBSを導入して型付けを進めています。LramaはCRubyのbuildに使われるという関係上、実行時に外部のgemに依存しないように実装しています。 なので型付けが自身に閉じており、型付けの恩恵も受けやすいのではないかと思います。 またsteepやrbsへのフィードバックもしています。他のゴールとの間に依存関係はありませんが、重要なゴールの一つです。
まとめ
"LSP"と"parse.y for Under graduate"というテーマをメインにロードマップを作りました。
ご覧の通りParser/Parser generator、Ruby/C言語/RBSといろいろな切り口のゴールがあります。
ruby-jp slackに#lr-parserというチャンネルがあるので、ご興味のある方ぜひぜひお越しください。
- 詳しくは Ruby の NODE を GC から卒業させた - クックパッド開発者ブログ を参照してください↩
- IELR(1)もPSLR(1)もJoel E. Dennyの発明で、PSLR(1)のためにIELR(1)を作ったのではないかと考えています↩
-
Bisonの文法は
%xxxというように%からはじまるtokenを多用するので、それに従っていれば多くの場合コンフリクトはしないはずですが、それでも気になります↩